
La Importancia de los Datos en la Logística y Distribución


En el dinámico mundo de la logística y distribución, el manejo efectivo de datos es un factor crucial para el éxito. En los últimos años, esta industria ha visto un aumento significativo en el volumen de información con la que cuenta, liderado principalmente por el incremento en las entregas (impulsado, post pandemia, por el comercio electrónico) y por la implementación de tecnología que permite medir cada paso de una encomienda. Este escenario obliga a las empresas a adoptar tecnologías de análisis y visualización de datos para mantenerse competitivas. Este artículo explora cómo la gestión de datos puede transformar las operaciones logísticas, facilitando la toma de decisiones informadas y optimizando cada etapa del proceso.
Importancia del Manejo de Datos en la Logística y Distribución
El manejo de datos en la logística y distribución permite a las empresas predecir la demanda con precisión, optimizar rutas de entrega y monitorear condiciones de almacenamiento en tiempo real (McKinsey & Company, Syscom). La capacidad de anticiparse a las necesidades del mercado y ajustar las operaciones logísticas en consecuencia resulta en una mayor eficiencia operativa y satisfacción del cliente.
Pero antes de llegar a estas predicciones, es recomendable que los sistemas internos estén preparados para recolectar, procesar y disponibilizar información para el apoyo de la toma de decisiones. Aquí nos referimos a contar con sistemas que faciliten responder preguntas como cuántas encomiendas están en tránsito, cuáles están atrasadas, y dónde están los cuellos de botella, de manera rápida y sencilla.
Qué maravilla sería contar con un reporte que fácilmente pueda contestar estas preguntas y hacer todos los drilldowns necesarios para tomar una decisión. ¿Cierto? Es posible, pero toma tiempo.
Desafíos en el Manejo de Grandes Volúmenes de Información
Disponibilizar información de manera sencilla es un desafío significativo debido al volumen y la variedad de datos generados. La calidad y precisión de estos datos son cruciales para evitar errores costosos. Además, la integración de múltiples sistemas de datos puede ser complicada, pero es esencial para una visión holística de la cadena de suministro (Emerald Insight, Syscom).
Este problema, principalmente técnico, se resuelve a través de la centralización de información en un repositorio central. Este repositorio es conocido por muchos nombres, como Data Lake, Data Mart o Data Warehouse (¡este último es el que más nos gusta a nosotros!). En palabras sencillas, es una base de datos que almacena información desde distintas fuentes utilizadas en la empresa y es capaz de disponibilizar información procesada para que usuarios no técnicos puedan analizarla de manera sencilla, muchas veces desde herramientas de visualización como Power BI o Tableau.
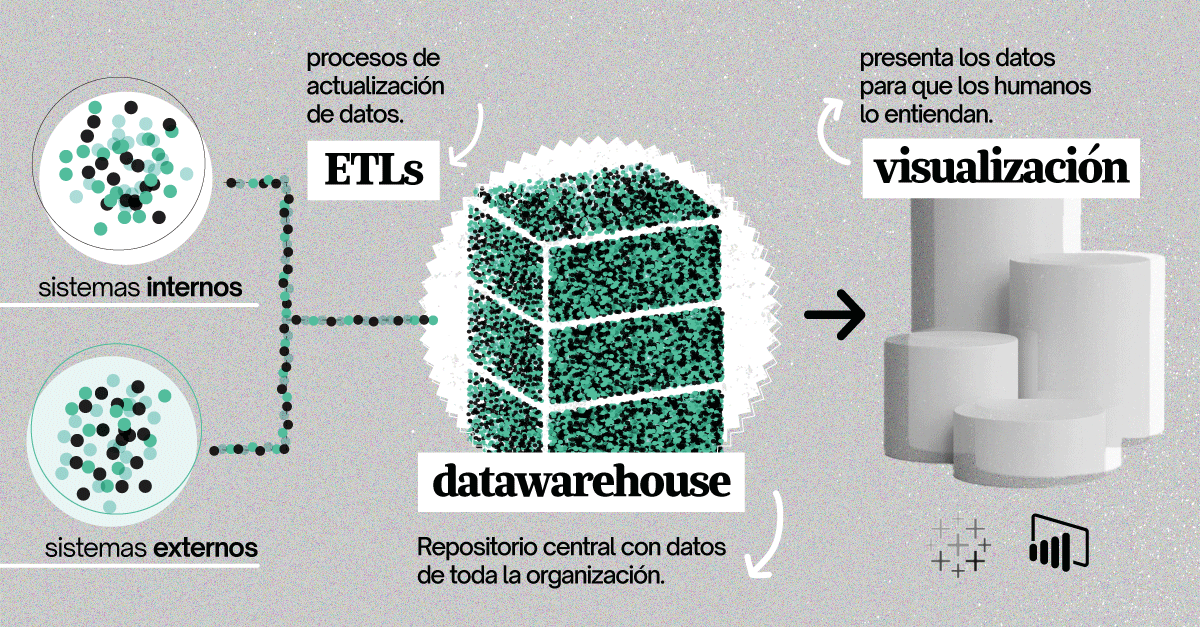
Los principales desafíos para construir este repositorio son:
- Integración de datos: Construir procesos que automáticamente se conecten a las distintas fuentes de información de la organización y traigan los datos necesarios al Data Warehouse en tiempo y forma necesarios. Estas integraciones suelen ser difíciles debido al alto volumen de datos y la necesidad de contar con los datos lo más cercano a tiempo real posible.
- Transformación de datos: Los datos en bruto deben ser transformados, idealmente dentro del Data Warehouse, aplicando todas las lógicas de negocio necesarias para quedar en un formato que facilite su análisis. Lo difícil aquí es entender bien estas reglas (por ejemplo, cálculo de Nivel de Servicio, NDS) y ejecutarlas sobre el gran volumen de datos con el que se cuenta.
- Visualización de datos: Una vez transformados los datos, estos pueden ser fácilmente conectados a herramientas de visualización con las cuales los podremos analizar desde distintas ópticas, pudiendo interactuar con ellos a través de filtros y segmentaciones. El desafío aquí es que la visualización debe ser muy precisa para ayudar a las personas a identificar problemas dentro de muchas cosas que están pasando.
Modelos Predictivos: El Siguiente Paso Después de la Visualización de Datos
Una vez que se han solucionado los desafíos de la visualización de datos y se cuenta con un sistema robusto de gestión y análisis de datos, las empresas pueden dar el siguiente paso: implementar modelos predictivos. Estos modelos permiten:
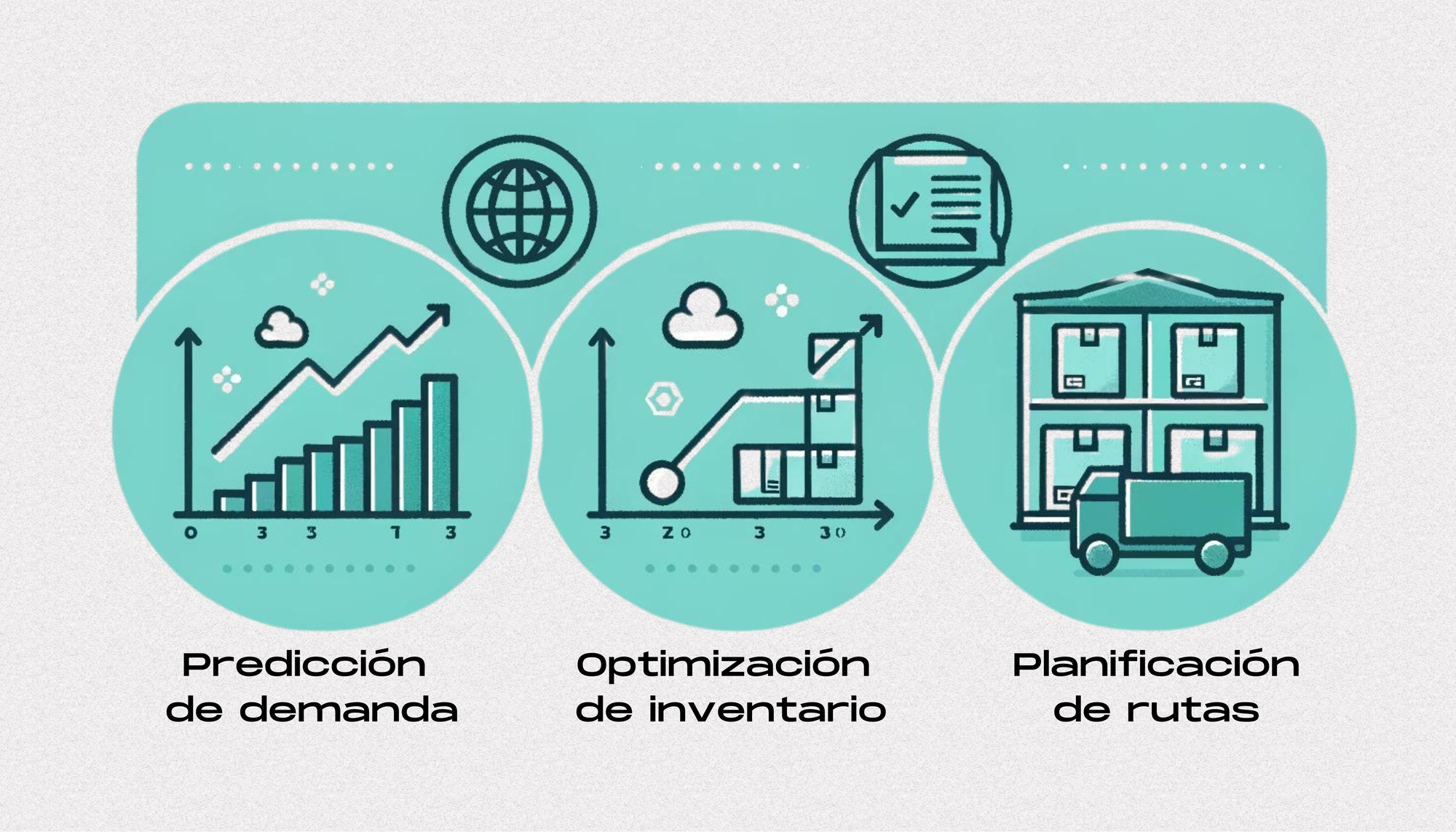
- Predecir Demanda: Utilizar algoritmos de machine learning para anticipar la demanda futura basándose en datos históricos y factores externos, como tendencias de mercado y comportamiento del consumidor.
- Optimización de Inventario: Mantener niveles óptimos de inventario, reduciendo tanto el exceso como la escasez de productos. Esto se traduce en una mayor eficiencia operativa y reducción de costos.
- Rutas de Entrega Eficientes: Identificar y planificar las rutas de entrega más eficientes, tomando en cuenta variables como el tráfico, el clima y la proximidad de los destinos.
- Mantenimiento Predictivo: Anticipar fallos en equipos y vehículos, programando el mantenimiento antes de que ocurran problemas graves. Esto reduce el tiempo de inactividad y los costos de reparación.
- Análisis de Riesgos: Evaluar y mitigar riesgos potenciales en la cadena de suministro, como interrupciones por eventos climáticos, cambios en la demanda o problemas con proveedores.
Al implementar estos modelos predictivos, las empresas de logística y distribución pueden no solo optimizar sus operaciones actuales, sino también prepararse mejor para el futuro, adaptándose rápidamente a cambios y mejorando continuamente su eficiencia y servicio al cliente.
Conclusión
Las empresas de este rubro no deben quedarse atrás. Deben invertir en equipos de datos que les ayuden a desarrollar estas capacidades. Cómo esto afecta a tu empresa. Si quieres saber más, no dudes en escribirnos: [email protected]